路由
(使用php-amqplib) 在上一节中,我们创建了一个简单的日志系统(logging system)。我们已经可以广播日志消息到多个接收者了。
在本节中,我们要给它增加一个功能-使它能够只订阅消息的一个子集。比如,只把严重的错误信息写入到日志文件(存储到磁盘)中,但同时仍然会把所有日志信息输出到控制台中。
绑定
在上一节中我们已经创建了绑定(bindings),代码如下:
$channel->queue_bind($queue_name,'logs');
绑定(bindings)是指交换器(exchange)和队列(queue)的关系。可以简单的理解为:这个队列对这个交换器中的消息感兴趣。
绑定的时候可以带一个额外的 routing_key 参数。为了避免与$channel::basic_publish的参数混淆,我们把它叫做 binding_key,所以我们这样使用key创建一个绑定:
$binding_key = 'black';
$channel->queue_bind($queue_name,$exchange_name,$binding_key);
binding key的意义取决于交换器的类型。我们之前使用过的fanout类型的交换器,会忽略这个值。
Direct 交换器
之前创建的日志系统分发所有消息到所有的消费者。我们打算扩展一下,使它可以过滤严重的消息。比如,我们只想在接收到严重错误的时候才写入到磁盘中,不在警告或普通的消息上浪费磁盘空间。
我们使用的是没有太多扩展性的fanout交换器,它仅能够简单的广播消息。
我们将要使用一个direct交换器代替fanout交换器。路由算法很简单-只有binding key完全匹配routing key的消息会进入队列。
为了说明,考虑如下的场景:
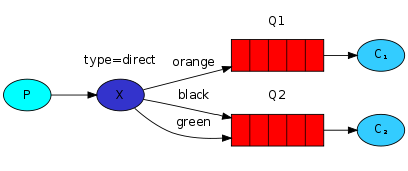
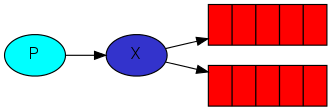
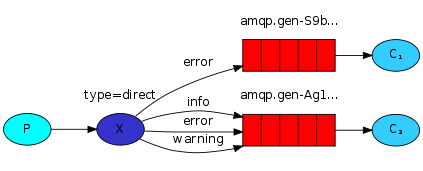
在这个场景中,我们可以看到direct类型的交换器X有两个队列,第一个队列使用orange作为binding key,第二个队列有两个绑定,一个是black另一个是green。
在这个场景中,当routing key为orange的消息发送到交换器,将会被路由到队列Q1。routing key为black或green的消息将会发送到Q2。其他的消息则会被丢弃。
多个绑定
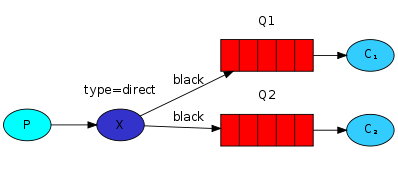
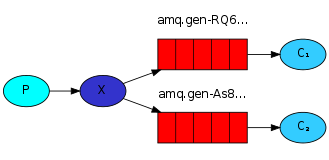
使用相同的binding key绑定多个队列是合法的。在这个例子中,我们会使用black作为binding key为X和Q1之间添加一个绑定。这样一来,direct 交换器就表现得跟fanout交换器一样,分发消息到匹配的队列。routing key为black的消息就会被分发到Q1和Q2。
发送日志
我们将要对日志系统使用这个模型,我们将要发送消息到一个direct交换器。将日志级别作为routing key。这样一来接收端程序就可以选择它想要接收的消息了。首先来看看发送日志。
和以往一样,需要创建一个交换器:
$channel->exchange_declare('direct_logs','direct',false,false,false);
然后准备发送消息:
$channel->exchange_declare('direct_logs','direct',false,false,false);
$channel->basic_publish($msg,'direct_logs',$severity);
为了简化,我们可以假定’severity’的值可以是’info’,‘warning’,‘error’中的一个。
订阅
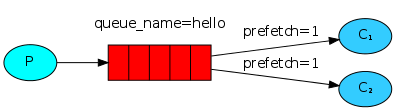
接收消息的脚本会跟之前一样正常工作,但是我们准备为每一个我们感兴趣的日志级别创建一个新的绑定。
foreach($severities as $severity){
$channel->queue_bind($queue_name,'direct_logs',$severity);
}
整合
emit_log_direct.php类的代码为:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPStreamConnection;
use PhpAmqpLib\Message\AMQPMessage;
$connection = new AMQPStremConnection('localhost',5672,'guest','guest');
$channel = $connection->channel();
$channel->exchange_declare('direct_logs','direct',false,false,false);
$severity = isset($argv[1]) && !empty($argv[1]) ? $argv[1] : 'info';
$data = implode(' ',array_slice($argv,2));
if(empty($data)) $data = “Hello World!”;
$msg = “[x] Sent ”,$severity,':',$data,” \n”;
$channel->close();
$connection->close();
?>
receive_logs_direct.php的代码为:
<?php
require_once __DIR__ . '/vendor/autoload.php';
use PhpAmqpLib\Connection\AMQPStreamConnection;
$connection = new AMQPStreamConnection('localhost',5672,'guest','guest');
$channel = $connection->channel();
$channel->exchange_declare('direct_logs','direct',false,false,false);
list($queue_name, ,) = $channel->queue_declare(“”,false,false,true,false);
$severities = array_slice($argv,1);
if(empty($severities)){
file_put_contents('php://stderr',”Usage:$argv[0][info][warning][error]\n”);
exit(1);
}
foreach($severities as $severity){
$channel->queue_bind($queue_name,'direct_logs',$severity);
}
echo '[*]Waiting for logs.To exit press CTRL+C',”\n”;
$callback = function($msg){
echo '[*]',$msg->delivery_info['routing_key'],':',$msg->body,”\n”;
};
$channel->basic_consume($queue_name,'',false,true,false,false,$callback);
while(count($channel->callbacks)){
$channel->wait();
}
$channel->close();
$connection->close();
?>
如果你想只保存’warning’或’error’(而不是’info’)级别的消息,只需要打开命令行输入:
php receive_logs_direct.php warning error > logs_from_rabbit.log
如果你想在屏幕上输出所有的消息,打开一个新的终端,输入:
php receive_logs_direct.php info warning error
[*]Waiting for logs.To exit press CTRL+C
例如,发送error消息,输入:
php emit_log_direct.php error "Run. Run. Or it will explode."
[x] Sent 'error':'Run. Run. Or it will explode.'
emit_log_direct.php源码 receive_logs_direct.php源码
转到第五节,查看如何监听基于模式的消息。
原文地址:Routing